

NVIDIA H100 NVL

Hopper Architecture
Securely Accelerate Workloads From Enterprise to Exascale
- 94GB HBM3 Memory
- MPC 350w-400w
NVIDIA H100 NVL は、NVLinkブリッジで接続された 2基の合計 188GB HBM3メモリ、帯域幅計 7.8TB/sを実現し、H100 NVL GPUを搭載したサーバでは、GPT-175Bモデルの性能を NVIDIA DGX A100システムの最大 12倍まで向上します。
製品仕様
| H100 SXM | H100 NVL | |
| FP64 | 34 teraFLOPS | 30 teraFLOPS |
| FP64 Tensor コア | 67 teraFLOPS | 60 teraFLOPS |
| FP32 | 67 teraFLOPS | 60 teraFLOPS |
| TF32 Tensor コア※ | 989 teraFLOPS | 835 teraFLOPS |
| BFLOAT16 Tensor コア※ | 1,979 teraFLOPS | 1,671 teraFLOPS |
| FP16 Tensor コア※ | 1,979 teraFLOPS | 1,671 teraFLOPS |
| FP8 Tensor コア※ | 3,958 TFLOPS | 3,341 TFLOPS |
| INT8 Tensor コア※ | 3,958 TOPS | 3,341 TOPS |
| GPU メモリ | 80GB | 94GB |
| GPU メモリ帯域幅 | 3.35TB/秒 | 3.9TB/秒 |
| デコーダー | 7 NVDEC 7 JPEG |
7 NVDEC 7 JPEG |
| 最大熱設計電力 | 最大 700W (構成可能) |
350-400W (構成可能) |
| マルチインスタンス GPU | 各 10GB 最大 7 MIG |
各 12GB 最大 14 MIG |
| フォーム ファクター | SXM | PCIe デュアルスロット 空冷 |
| 相互接続 | NVLink:900GB/秒 PCIe Gen5:128GB/秒 |
NVLink:600GB/秒 PCIe Gen5:128GB/秒 |
| サーバー オプション | 4 または 8GPU搭載の NVIDIA HGX H100パートナー および NVIDIA-Certified Systems 8 GPU搭載の NVIDIA DGX H100 |
1~8 GPU搭載の パートナーおよび NVIDIA Certified Systems |
| NVIDIA AI Enterprise | アドオン | 含む |
疎性あり
Enterprise-Ready Utilization
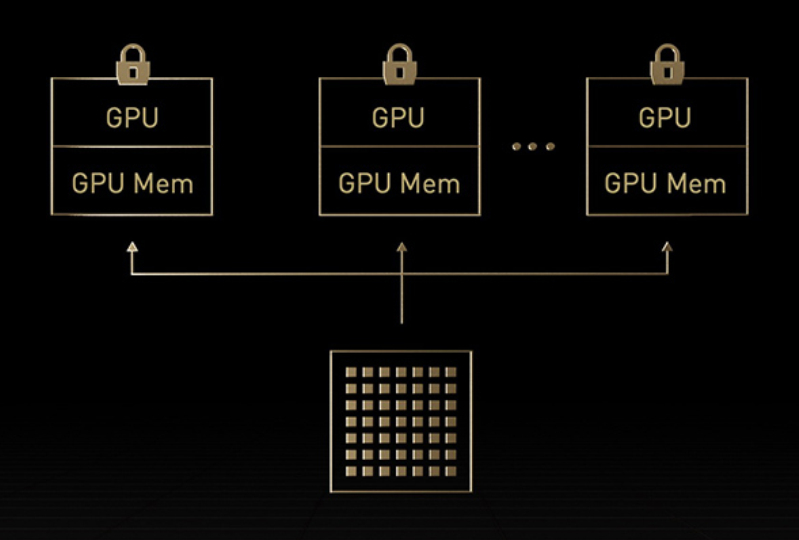
管理者はリソースの利用率(ピークと平均の両方)を最大化することを目指しています。多くの場合、コンピューティングを動的に再構成し、使用中のワークロードに合わせてリソースを正しいサイズに変更します。
H100の第 2世代 MIGでは、7個ものインスタンスに分割することで各 GPUの利用率を最大化します。コンフィデンシャル コンピューティング対応の H100 では、マルチテナントをエンドツーエンドで安全に利用できます。クラウド サービス プロバイダー (CSP) 環境に最適です。
H100 と MIG なら、インフラストラクチャ管理者は GPU アクセラレーテッド インフラストラクチャを標準化できて、同時に、GPU リソースを非常に細かくプロビジョニングできます。正しい量のアクセラレーテッド コンピューティングが安全に開発者に与えられ、GPU リソースの利用を最適化します。
NVIDIA コンフィデンシャルコンピューティング
使用中の AI ワークロードの機密性と完全性の保護
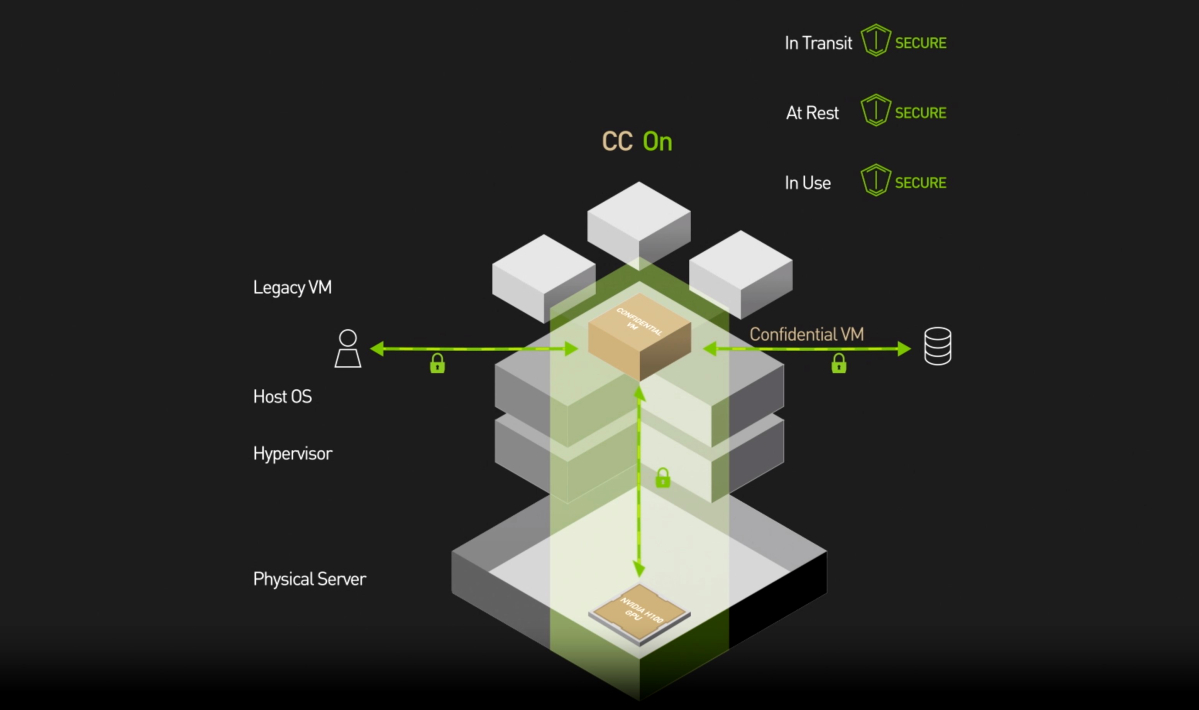
データや AIモデル、アプリケーションの使用時は、オンプレミスやクラウド等のいずれに展開されていても、外部からの攻撃や内部の脅威に対し脆弱となります。NVIDIA Hopperアーキテクチャで導入された画期的なセキュリティ機能である NVIDIA コンフィデンシャルコンピューティングは、AIワークロード向けの NVIDIA H100 Tensor コア GPU のかつてない高速化をユーザーに利用させながらそのような脅威を軽減します。強力なハードウェアベースのセキュリティを利用し、不正アクセスから機密データや専有の AIモデルを保護します。
NVIDIA H100 NVL データシート

弊社では、科学技術計算や解析などの各種アプリケーションについて動作検証を行い、
すべてのセットアップをおこなっております。
お客様が必要とされる環境にあわせた最適なシステム構成をご提案いたします。