

NVIDIA A100 Tensor Core GPU

NVIDIA A100 Tensor Core GPU PCI-Express 接続版にメモリ容量を 2倍にした NVIDIA A100-PCIe 80GB HBM2e が追加されました。メモリ帯域は約 25%拡張され 1,935GB/sに達し、今まで以上のモデルやデータセットにも対応します。
NVIDIA A100-PCIe 80GB HBM2e と NVIDIA A100-PCIe 40GB HBM2 はあらゆる規模で高速化を実現し、AI、データ分析、HPC に最高のパフォーマンスをもたらします。
NVIDIA Ampere アーキテクチャで設計された NVIDIA A100 は、前世代と比較して最大 20倍のパフォーマンスを発揮し、7つの GPUインスタンスに分割して変化する需要に合わせて動的に調整できます。


製品仕様
|
NVIDIA A100 |
NVIDIA A100 |
|||
| Peak FP64 | 9.7 TF | |||
| Peak FP64 Tensor Core | 19.5 TF | |||
| Peak FP32 | 19.5 TF | |||
| Peak TF32 Tensor Core | 156 TF | 312 TF* | |||
| Peak BFLOAT16 Tensor Core | 312 TF | 624 TF* | |||
| Peak FP16 Tensor Core | 312 TF | 624 TF* | |||
| Peak INT8 Tensor Core | 624 TOPS | 1,248 TOPS* | |||
| Peak INT4 Tensor Core | 1,248 TOPS | 2,496 TOPS* | |||
| GPU Memory | 40 GB | 80 GB | 40 GB | 80 GB |
| GPU Memory Bandwidth | 1,555 GB/s | 2,039 GB/s | 1,555 GB/s | 1,935 GB/s |
| Interconnect | NVIDIA NVLink 600 GB/s** PCIe Gen4 64 GB/s |
NVIDIA NVLink 600 GB/s** PCIe Gen4 64 GB/s |
||
| Multi-instance GPUs |
Up to 7MIGs @5GB |
Up to 7MIGs @10GB | Up to 7MIGs @5GB | Up to 7MIGs @10GB |
| Form Factor | SXM | PCIe |
||
| Max TDP Power | 400W | 250W | 300W | |
* With sparsity
** SXM GPUs via HGX A100 server boards, PCIe GPUs via NVLink Bridge for up to 2-GPUs
ディープラーニング トレーニング
対話型 AIといった次のレベルの課題に挑む AIモデルは、爆発的に複雑化しており、モデルのトレーニングには、大規模な計算処理能力とスケーラビリティが必要になります。
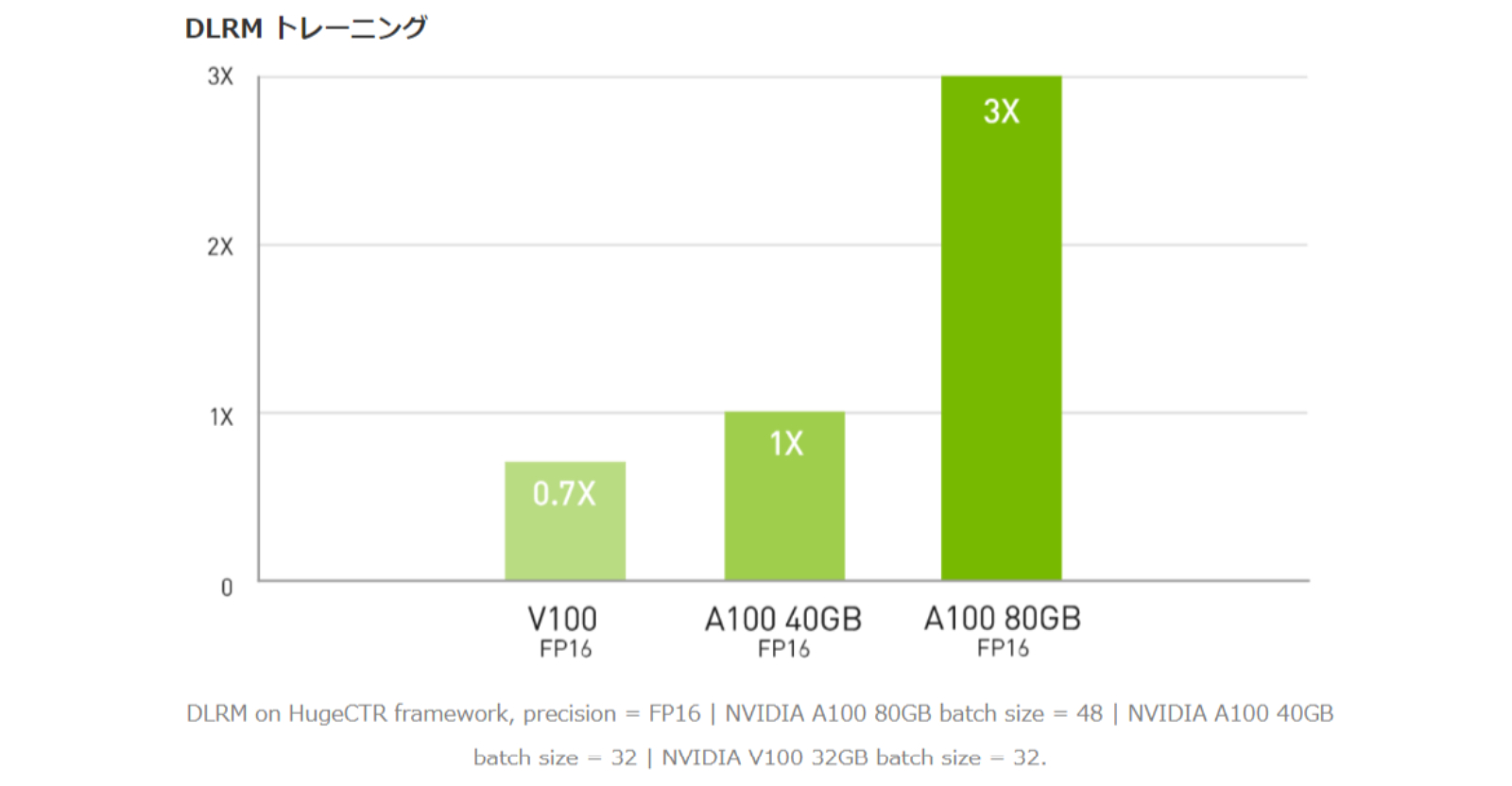
NVIDIA A100の Tensorコア と Tensor Float (TF32) を利用することで、NVIDIA Voltaと比較して最大 20倍のパフォーマンスがコードを変更することなく得られます。加えて、Automatic Mixed Precisionと FP16の活用でさらに 2倍の高速化が可能になります。
最大級のモデルで最大 3倍高速な AIトレーニング
ディープラーニング推論
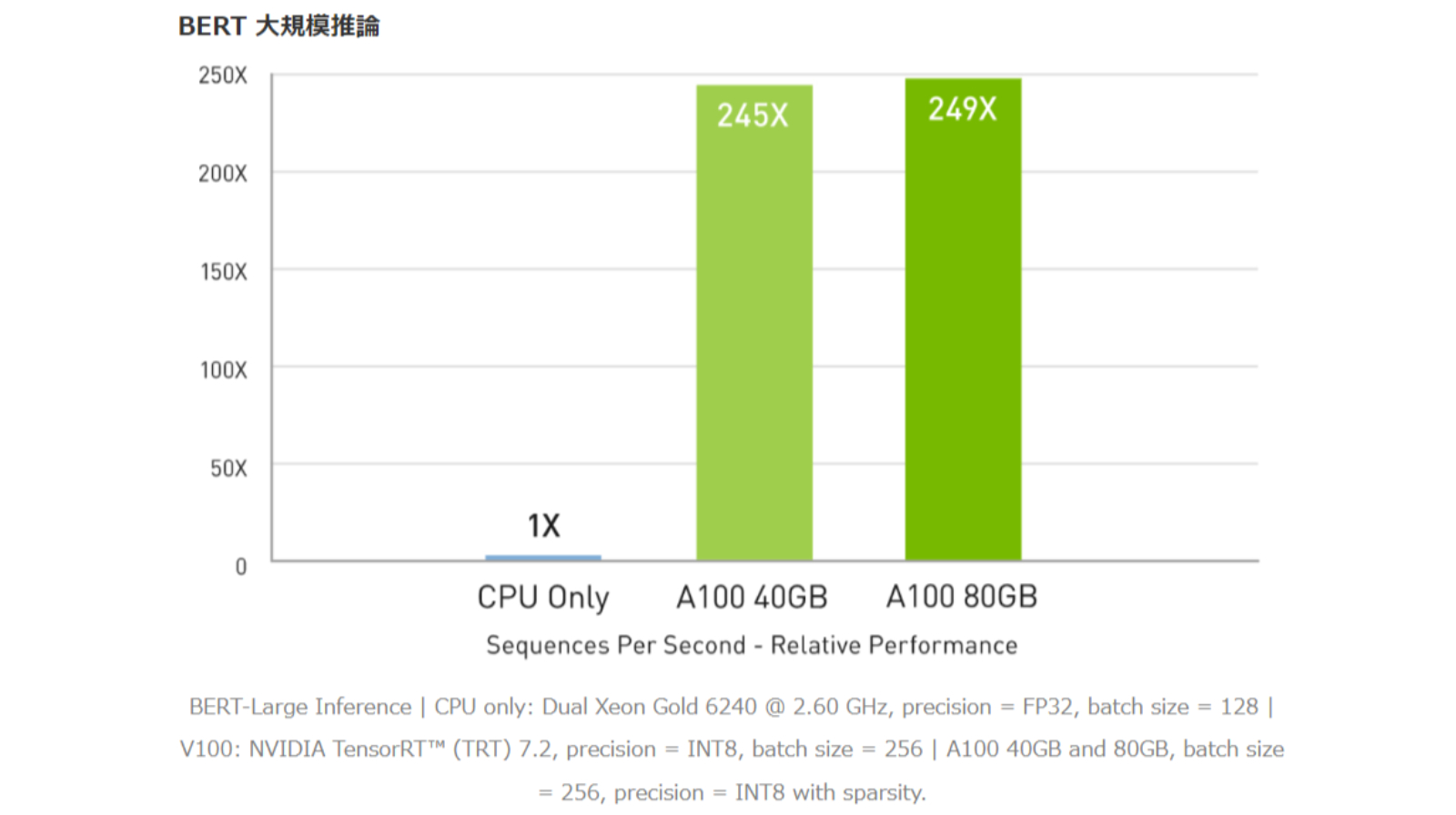
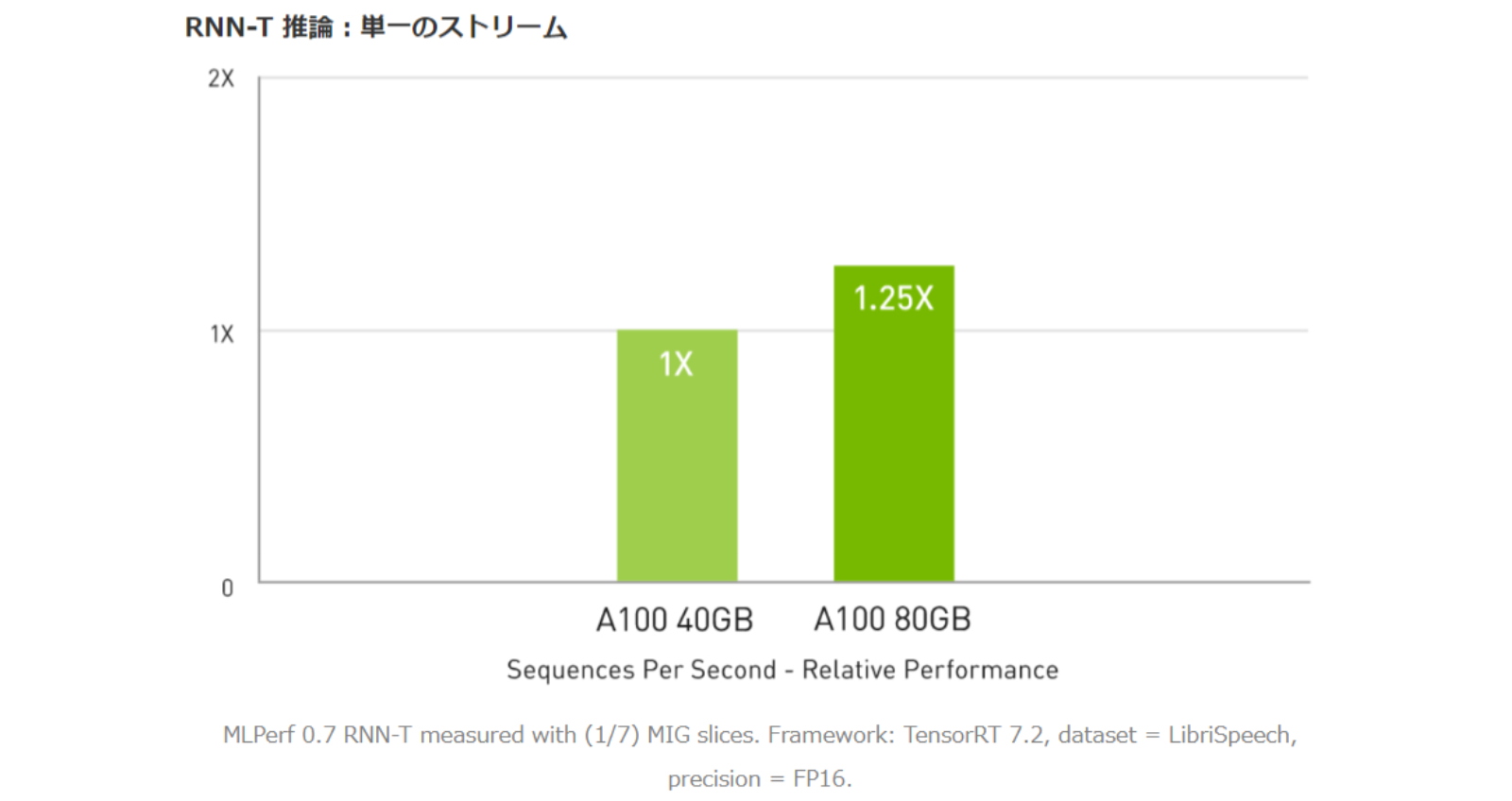
A100には、推論ワークロードを最適化する画期的な機能が導入されています。FP32から INT4まであらゆる精度を加速します。マルチインスタンス GPU (MIG) テクノロジにより、1個の A100で複数のネットワークを同時に動作できるため、コンピューティングリソースの使用率が最適化されます。また、構造化スパース性により、A100による数々の推論性能の高速化に加え、最大 2倍のパフォーマンスがもたらされます。メモリ容量の大きな A100 80GBでは各 MIGのサイズが 2倍になり、自動音声認識用の RNN-Tといった、バッチサイズが制約された非常に複雑なモデルでは、A100 40GBに比べて最大 1.25倍のスループットが得られます。
CPUと比較して最大 249倍高速な AI推論パフォーマンス
A100 40GBと比較して最大 1.25倍高速な AI推論パフォーマンス
ハイパフォーマンス コンピューティング
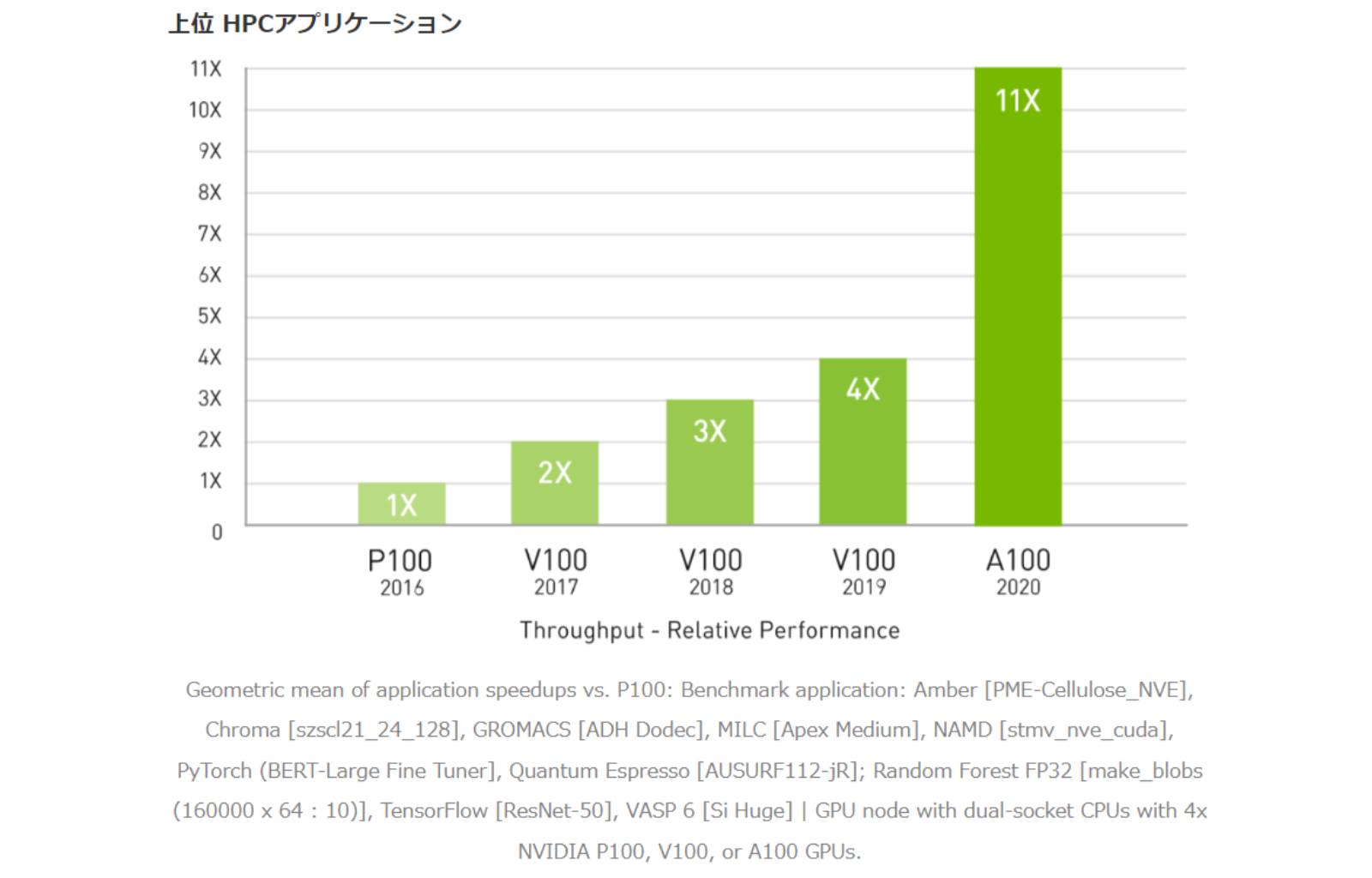
科学者たちは日々、私たちを取り巻いている世界をより良く理解し、その謎を解き明かすためのシミュレーションに関心を向けています。NVIDIA A100は、Tensorコアを導入することで HPCパフォーマンスの飛躍を実現しています。80GBのGPUメモリとNVIDIA A100を組み合わせることで、研究者は10時間かかる倍精度シミュレーションをわずか4時間たらずに短縮できます。HPCアプリケーションで TF32を活用すれば、単精度の密行列積演算のスループットが最大 11倍向上します。
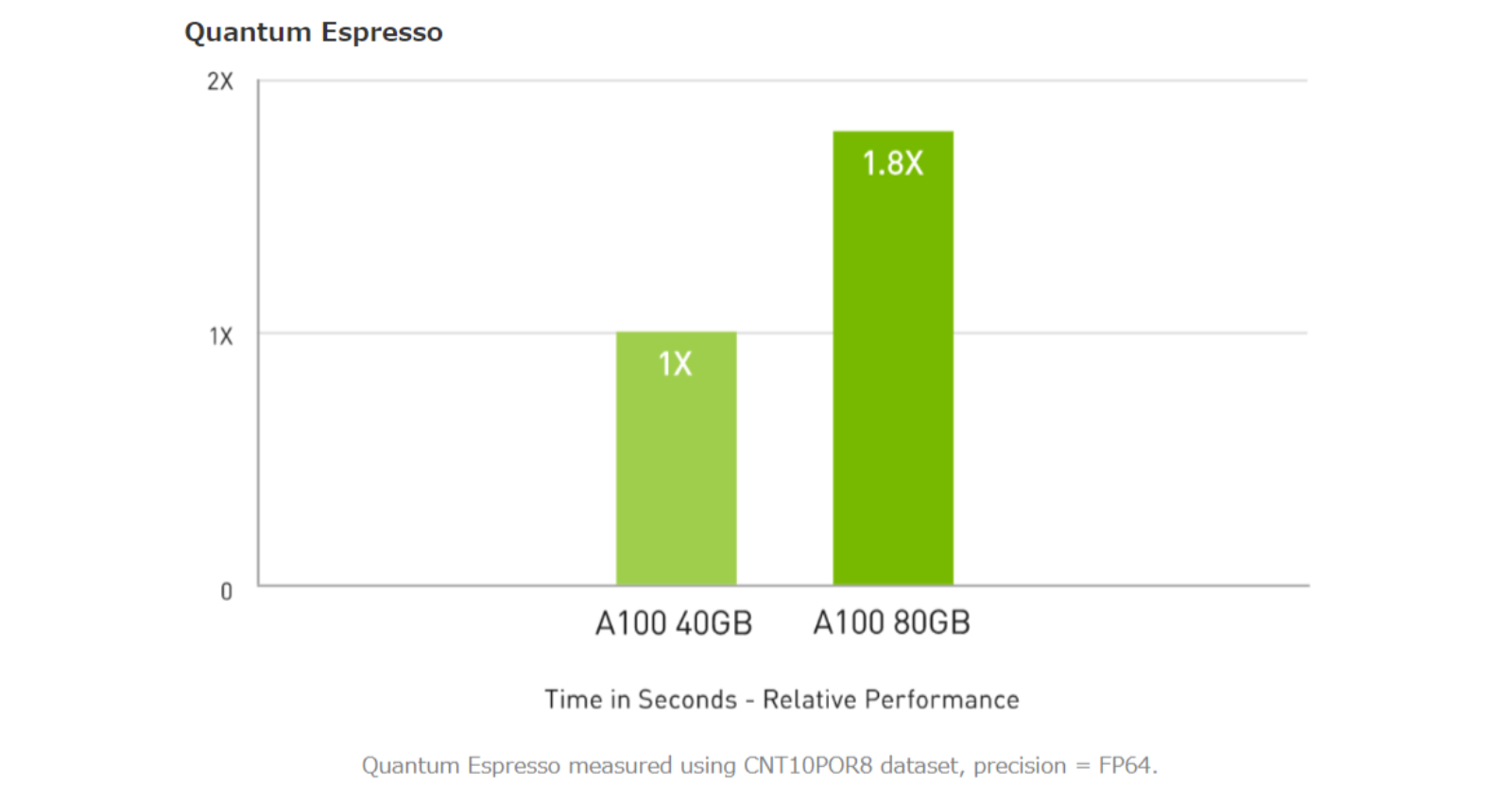
大規模データセットを扱う HPC アプリケーションでは、メモリが追加された A100 80GBにより、マテリアルシミュレーションの Quantum Espressoにおいて最大 2倍のスループットの増加を実現します。この膨大なメモリ量とメモリ帯域幅により、A100 80GBは次世代のワークロードに最適なプラットフォームとなっています。
4年間で 11倍の HPCパフォーマンス
HPCアプリケーションで最大 1.8倍高速なパフォーマンス
ハイパフォーマンス データ分析
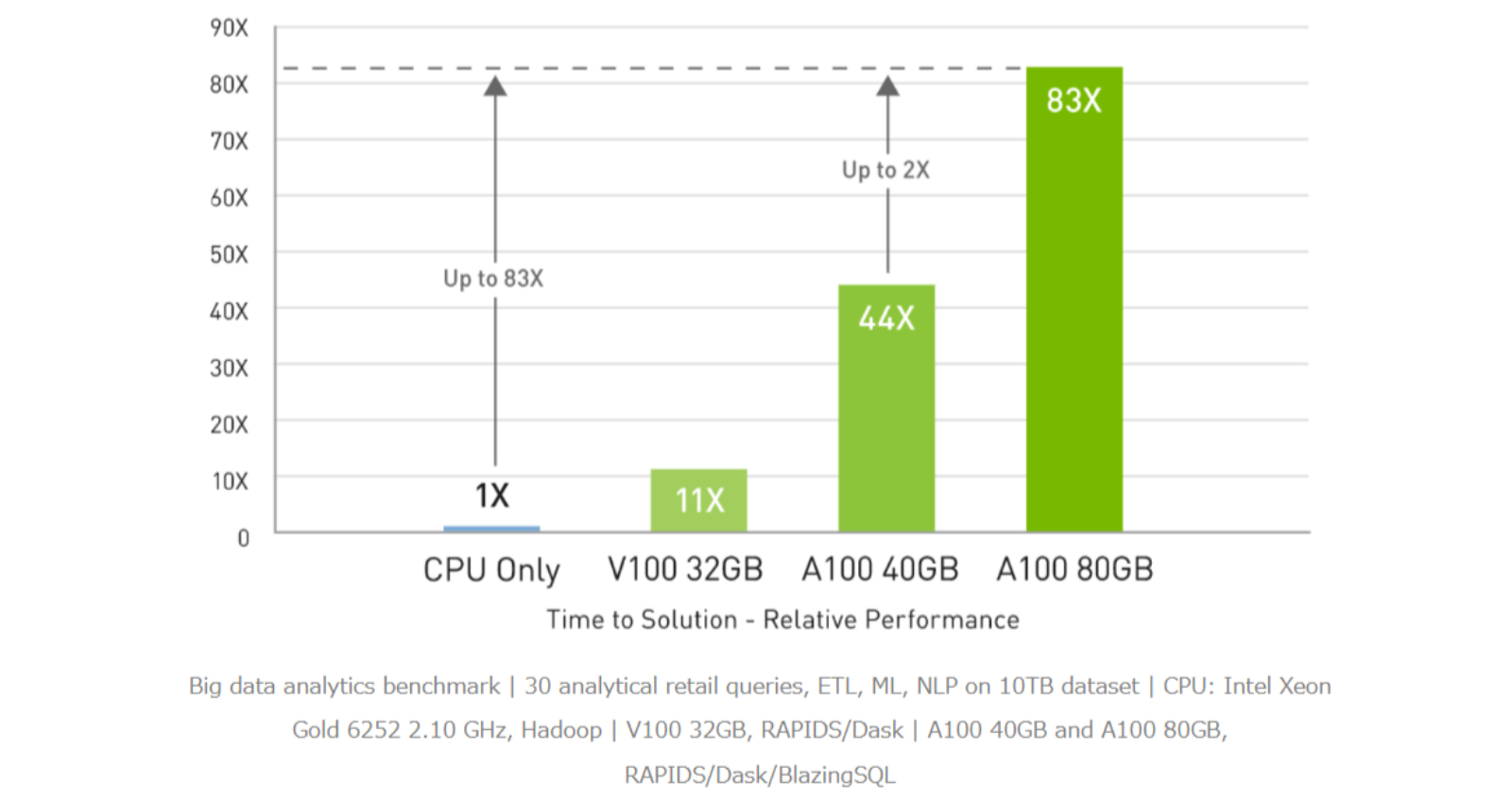
A100 80GBはビッグデータ分析ベンチマークで、CPUの 83倍高いスループット、A100 40GBに対しては 2倍高いスループットでインサイトをもたらします。データセットサイズが爆発的に増える今のワークロードに最適です。
ビッグデータ分析ベンチマークで CPUより最大 83倍、A100 40GBより 2倍高速
企業で効率的に利用
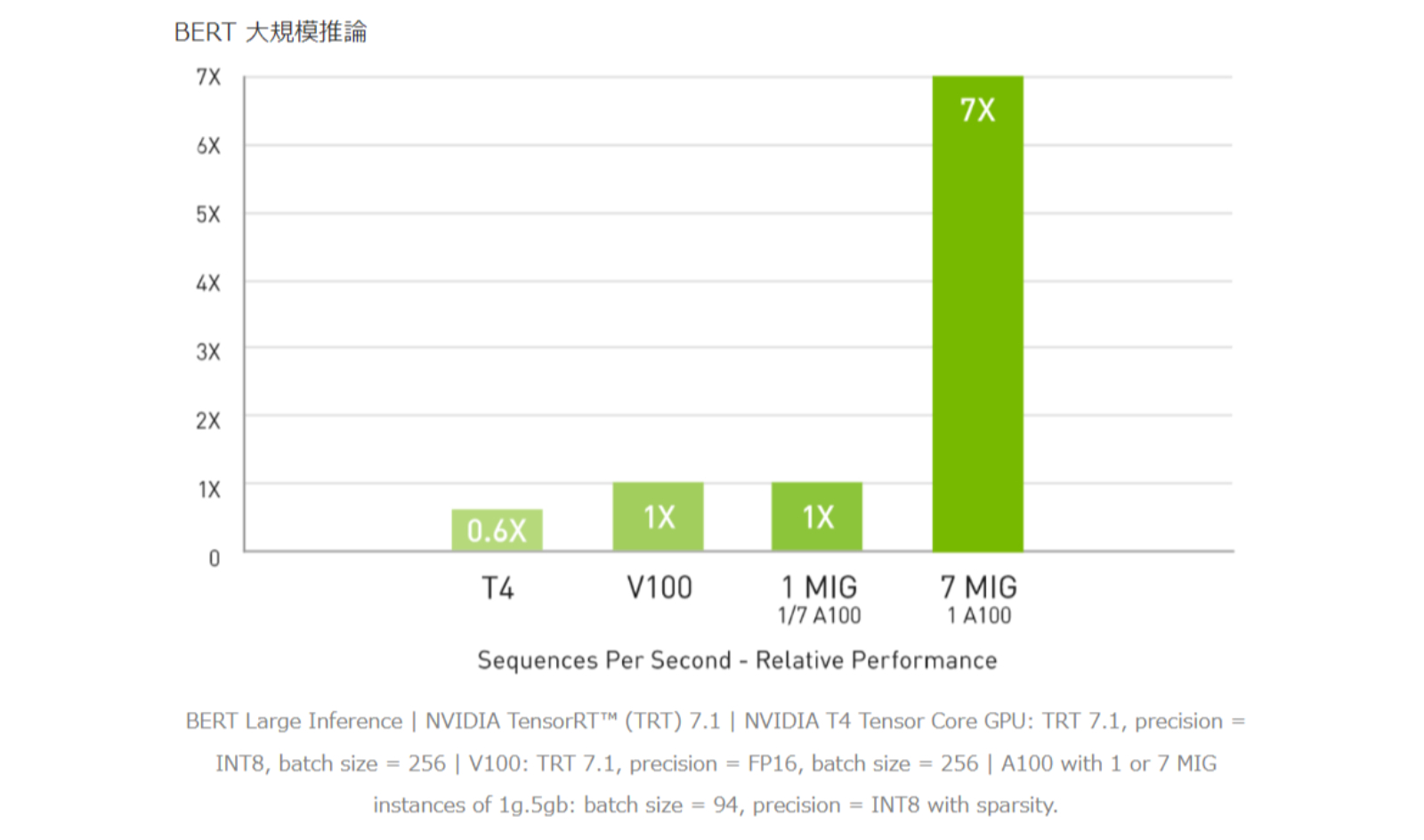
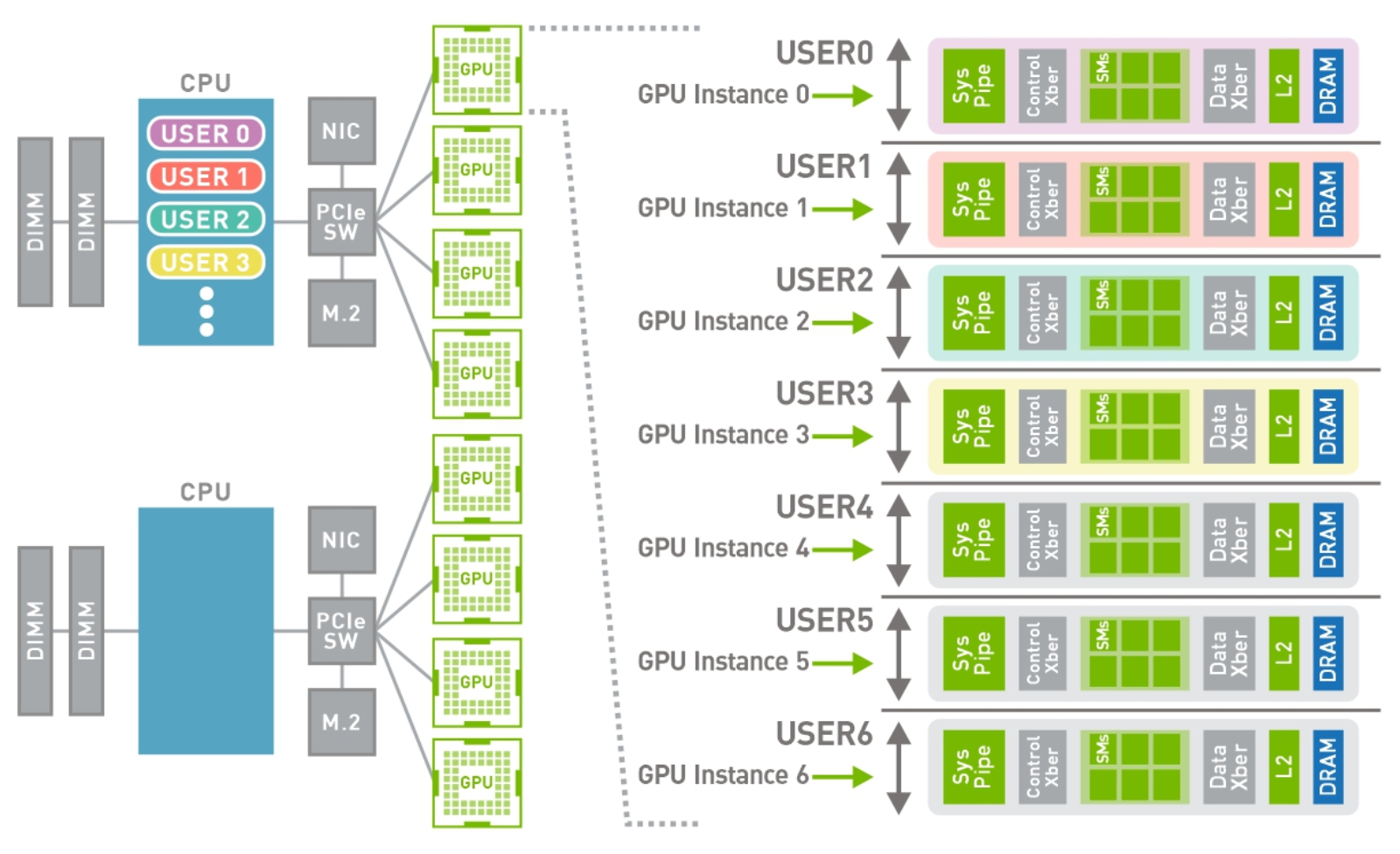
A100と MIGの組み合わせにより、GPU活用インフラストラクチャを最大限に利用できます。MIGを利用することで、A100 GPUを 7つもの独立したインスタンスに分割できます。複数のユーザーが GPUアクセラレーションを利用できます。A100 40GBでは、各 MIGインスタンス に最大 5GBまで割り当てることができ、A100 80GBではメモリ容量が増えたことで、そのサイズは 2倍の 10GBになります。
マルチインスタンス GPU (MIG) による 7倍の推論スループット
CSP Multi-Instance GPU(MIG)
NVIDIA A100-PCIe 用 NVLINK BRIDGE – 2Way 2Slot

NVIDIA A100 Tensor Core GPU Architecture – WHITEPAPER


NVIDIA A100 Tensor Core GPU Architecture – Product Brief


弊社では、科学技術計算や解析などの各種アプリケーションについて動作検証を行い、
すべてのセットアップをおこなっております。
お客様が必要とされる環境にあわせた最適なシステム構成をご提案いたします。